kafka 介绍
kafka是一款分布式、支持分区的、多副本,基于zookeeper协调的分布式消息系统。最大的特性就是可以实时处理大量数据来满足需求。
我们将消息的发布(publish)称作 producer,将消息的订阅(subscribe)表述为 consumer,将中间的存储阵列称作 broker(代理),这样就可以大致描绘出这样一个场面:

生产者将数据生产出来,交给 broker 进行存储,消费者需要消费数据了,就从broker中去拿出数据来,然后完成一系列对数据的处理操作。
官网中关于分布式架构图如下:
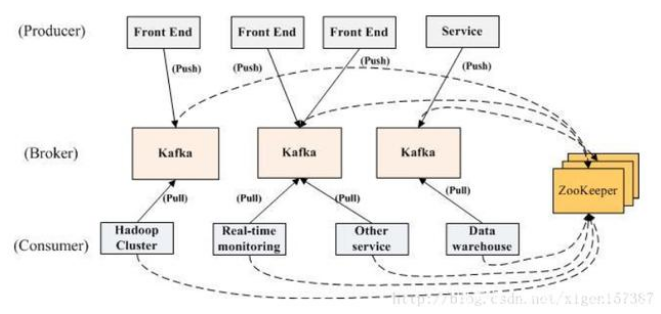
多个 broker 协同合作,producer 和 consumer 部署在各个业务逻辑中被频繁的调用,三者通过 zookeeper管理协调请求和转发。这样一个高性能的分布式消息发布订阅系统就完成了。
Kafka 基本概念
topic:主题
Topic 被称为主题,在 kafka 中,使用一个类别属性来划分消息的所属类,划分消息的这个类称为 topic。topic 相当于消息的分配标签,是一个逻辑概念。主题好比是数据库的表,或者文件系统中的文件夹。
partition:分区
partition 译为分区,topic 中的消息被分割为一个或多个的 partition,它是一个物理概念,对应到系统上的就是一个或若干个目录,消息以追加的形式写入分区,先后以顺序的方式读取。
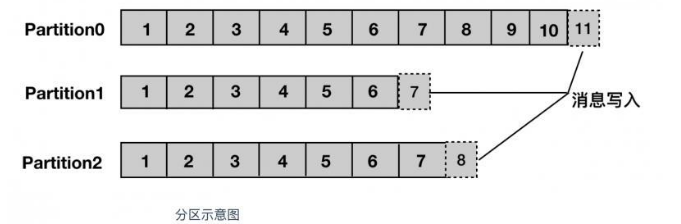
分区可以分布在不同的服务器上,也就是说,一个主题可以跨越多个服务器,以此来提供比单个服务器更强大的性能。
segment:分段
Segment 被译为段,将 Partition 进一步细分为若干个 segment,每个 segment 文件的大小相等。
broker:服务器
Kafka 集群包含一个或多个服务器,每个 Kafka 中服务器被称为 broker。
broker 接收来自生产者的消息,为消息设置偏移量,并提交消息到磁盘保存。
broker 为消费者提供服务,对读取分区的请求作出响应,返回已经提交到磁盘上的消息。
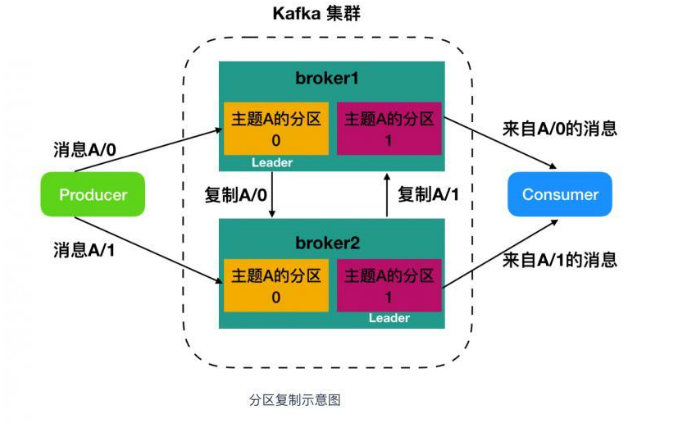
集群中,一个分区从属于一个 Leader,但是一个分区可以分配给多个 broker(非Leader),这时候会发生分区复制。这种复制的机制为分区提供了消息冗余,如果一个 broker 失效,那么其他活跃用户会重新选举一个 Leader 接管。
producer:生产者
生产者,即消息的发布者,其会将某 topic 的消息发布到相应的 partition 中。生产者在默认情况下把消息均衡地分布到主题的所有分区上,而并不关心特定消息会被写到哪个分区。
consumer:消费者
消费者,即消息的使用者,一个消费者可以消费多个 topic 的消息,对于某一个 topic 的消息,其只会消费同一个 partition 中的消息
kafka单机部署与启动
前提:
安装JDK 1.8+
安装过程参考 《JDK1.8安装与配置》安装zookeeper
Kafka 的底层使用 Zookeeper 储存元数据,确保一致性,所以安装 Kafka 前需要先安装 Zookeeper,安装过程参考 《zookeeper安装与使用》
部署与启动
下载kafka_2.13-3.2.0.tgz并上传到服务器
wget https://dlcdn.apache.org/kafka/3.2.0/kafka_2.13-3.2.0.tgzv
网盘下载地址:
kafka_2.13-3.2.0.tgz到/usr/local/kafka
mkdir -p /usr/local/kafka tar -zxvf kafka_2.13-3.2.0.tgz -C /usr/local/kafka mkdir -p /usr/local/kafka/kafka-logs cd /usr/local/kafka/kafka_2.13-3.2.0
编辑配置文件
config/server.propertiesbroker.id=0 # 初始是0,每个 server 的broker.id 都应该设置为不一样的,就和 myid 一样 我的三个服务分别设置的是 1,2,3 listeners=PLAINTEXT://127.0.0.1:9092 log.dirs=/usr/local/kafka/kafka-logs #设置zookeeper的连接端口,其中设置kafka为zookeeper的根节点 zookeeper.connect=localhost:2181/kafka配置项含义
broker.id=0 #当前机器在集群中的唯一标识,和zookeeper的myid性质一样
port=9092 #当前kafka对外提供服务的端口默认是9092
host.name=192.168.x.x #这个参数默认是关闭的,在0.8.1有个bug,DNS解析问题,失败率的问题。
num.network.threads=3 #这个是borker进行网络处理的线程数
num.io.threads=8 #这个是borker进行I/O处理的线程数
log.dirs=/usr/local/kafka/kafka-logs #消息持久化存放的目录
socket.send.buffer.bytes=102400 #发送缓冲区buffer大小,数据不是一下子就发送的,先回存储到缓冲区了到达一定的大小后在发送,能提高性能
socket.receive.buffer.bytes=102400 #kafka接收缓冲区大小,当数据到达一定大小后在序列化到磁盘
socket.request.max.bytes=104857600 #这个参数是向kafka请求消息或者向kafka发送消息的请请求的最大数,这个值不能超过java的堆栈大小
num.partitions=1 #默认的分区数,一个topic默认1个分区数
log.retention.hours=168 #默认消息的最大持久化时间,168小时,7天
message.max.byte=5242880 #消息保存的最大值5M
default.replication.factor=2 #kafka保存消息的副本数,如果一个副本失效了,另一个还可以继续提供服务
replica.fetch.max.bytes=5242880 #取消息的最大值5M
log.segment.bytes=1073741824 #这个参数是:因为kafka的消息是以追加的形式落地到文件,当超过这个值的时候,kafka会新起一个文件log.
retention.check.interval.ms=300000 #每隔300000毫秒去检查上面配置的log失效时间(log.retention.hours=168 ),到目录查看是否有过期的消息如果有,删除
log.cleaner.enable=false #是否启用log压缩,一般不用启用,启用的话可以提高性能
zookeeper.connect=127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183 #设置zookeeper的连接端口
启动kafka
前台运行
bin/kafka-server-start.sh config/server.properties以守护线程的方式后台运行
bin/kafka-server-start.sh -daemon config/server.properties遇到报错:
The Cluster ID UXw3eh4-Q0CC7_IYmYgD9A doesn't match stored clusterId Some(lL6u1m32TQ2RlepuSw1brQ) in meta.properties. The broker is trying to join the wrong cluster. Configured zookeeper.connect may be wrong.解决方法:
rm /usr/local/kafka/kafka-logs/meta.properties退出后台运行的kafka:
bin/kafka-server-stop.sh
检测kafka是否已经开启
ps -ef | grep kafka netstat -anp | grep 9092查看zookeeper的节点数据
[zk: localhost:2181(CONNECTED) 1] ls / [apps, kafka, zookeeper]
kafka 使用
kafka-topics.sh 用于管理主题
Create, delete, describe, or change a topic
创建主题
执行以下命令创建名为“test-mt”的topic,这个topic只有一个partition,并且备份因子也设置为1
./kafka-topics.sh --create --bootstrap-server 127.0.0.1:9092 --replication-factor 1 --partitions 1 --topic test-mt获取主题列表
./kafka-topics.sh --list --bootstrap-server 127.0.0.1:9092查看指定主题详细信息
./kafka-topics.sh --describe --bootstrap-server 127.0.0.1:9092 --topic test-mt删除主题
./kafka-topics.sh --delete --bootstrap-server 127.0.0.1:9092 --topic test-mt生产与消费
kafka-console-producer.sh 生产者
kafka自带了一个producer命令客户端,可以从本地文件中读取内容,或者我们也可以以命令行中直接输入内容,并将这些内容以消息的形式发送到kafka集群中。在默认情况下,每一个行会被当做成一个独立的消息。使用kafka的发送消息的客户端,指定发送到的kafka服务器地址和topic
启动生产者,以命令输入消息
./kafka-console-producer.sh --broker-list 127.0.0.1:9092 --topic test-mtkafka-console-consumer.sh 消费者
对于consumer,kafka同样也携带了一个命令行客户端,会将获取到内容在命令中进行输出, 默认是消费最新的消息 。使用kafka的消费者消息的客户端,从指定kafka服务器的指定topic中消费消息
启动消费者,消费消息
方式一:从最后一条消息的偏移量+1开始消费
./kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic test-mt方式二:从头开始消费
./kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --from-beginning --topic test-mt
通过python-api操作kafka
pip install kafka-python消费者
kf_comsumer.pyfrom kafka import KafkaConsumer consumer=KafkaConsumer('test-mt',bootstrap_servers='127.0.0.1:9092') for msg in consumer: print(msg.value.decode())同时订阅多个主题时
from kafka import KafkaConsumer consumer=KafkaConsumer(bootstrap_servers='127.0.0.1:9092') consumer.subscribe(topics=('test-mt','test-pt')) print(consumer.topics()) for msg in consumer: print(msg.value.decode())生产者
kf_producerfrom kafka import KafkaProducer import json producer = KafkaProducer( value_serializer=lambda v: json.dumps(v).encode('utf-8'), bootstrap_servers=['127.0.0.1:9092'] ) msg_dict = { "operatorId": "test", "terminalId": "123", "terminalCode": "456", "terminalNo": "1111", } producer.send("test-mt",msg_dict) producer.close()

转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。
