memtier_benchmark 介绍
memtier_benchmark是Redis Labs推出的一款命令行工具,它能够产生各种各样的流量模式,可以对Memcached和Redis实例进行基准测试。
memtier-benchmark可以根据您的需求生成多种结构的数据对数据库进行压力测试,帮助您了解目标数据库的性能极限。其部分功能特性如下。
支持Redis和Memcached数据库测试。
支持多线程、多客户端测试。
可设置测试中的读写比例(SET: GET Ratio)。
可自定义测试中键的结构。
支持设置随机过期时间。
了解memtier_benchmark更多详情,请访问https://github.com/RedisLabs/memtier_benchmark。
参考文档:
memtier_benchmark 安装
环境:阿里云 CentOS 7.6
[root@iZwz9f92w7soch5m251ghgZ ~]# lsb_release -a
LSB Version: :core-4.1-amd64:core-4.1-noarch
Distributor ID: CentOS
Description: CentOS Linux release 7.6.1810 (Core)
Release: 7.6.1810
Codename: Core通过源码安装(在线安装依赖)
编译安装环境准备,脚本如
1-install_dependence_with_yum.sh:#! /bin/bash # 安装编译所需的工具 yum install -y autoconf automake make gcc-c++ # 安装需要的依赖库 yum install -y pcre-devel zlib-devel openssl-devel libevent-devel下载memtier_benchmark.tar.gz
git clone https://github.com/RedisLabs/memtier_benchmark.git或网盘下载:https://pan.baidu.com/s/1D1vYIrQZNSCEgti9MgOCCw?pwd=rzwu
源码编译与安装,脚本如
3-install_memtier_with_source.sh:#! /bin/bash # 解压源码 tar -zxvf memtier_benchmark.tar.gz # 编译源码 cd memtier_benchmark autoreconf -ivf # 更新已经生成的配置文件,使用autoreconf命令可以重复编译指定目录下的系统文件 ./configure --prefix=/usr/local/memtier # 配置安装目录,把所有资源文件(可执行文件,库文件,配置文件,其他资源)放在/usr/local/memtier目录,不会凌乱 # 移植软件只需拷贝整个目录到另外一个机器即可(相同的操作系统) make # 编译生成可执行文件memtier_benchmark make install # 安装到系统中 # 配置环境变量[可选] #echo "export PATH=/usr/local/memtier/bin:\${PATH}" >> /etc/profile #source /etc/profile网盘安装包使用说明
网盘链接:https://pan.baidu.com/s/1-R8UAh0drsBxMi6tva9w_A?pwd=dk68
# 使用说明 ## 下载安装包“mb_online.tar.gz”后,解压如下: drwxr-xr-x 3 root root 4096 Jul 19 10:07 centos7.x drwxr-xr-x 3 root root 4096 Jul 19 10:06 centos8.x -rw-r--r-- 1 root root 44 Jul 19 10:05 readme.txt ## 根据操作系统,进入相应目录内,这里以centos7.6为例,进入centos7.x目录 -rwxr-xr-x 1 root root 189 Jul 19 10:07 1-install_dependence_with_yum.sh -rwxr-xr-x 1 root root 857 Jul 19 10:05 3-install_memtier_with_source.sh -rw-r--r-- 1 root root 1372341 Jul 19 10:05 memtier_benchmark.tar.gz -rw-r--r-- 1 root root 458 Jul 19 10:05 readme.txt drwxr-xr-x 4 root root 4096 Jul 19 10:05 run ################## 情况一:memtier_benchmark 源码编译安装 ############## ./1-install_dependence_with_yum.sh ./3-install_memtier_with_source.sh /usr/local/memtier/bin/memtier_benchmark ################## 情况二:使用已经编译好的memtier_benchmark ############## ### 进入run目录,检查memtier_benchmark所需要得动态链接库(so) ldd memtier/bin/memtier_benchmar ### 若发现如下问题: libevent-2.0.so.5 => not found libevent_openssl-2.0.so.5 => not found ### 添加软链接即可 ./add_link_for_libevent.sh ######################################################################## ## 检查memtier_benchmark是否可用 [root@iZwz9f92w7soch5m251ghgZ run]# memtier/bin/memtier_benchmark --help Usage: memtier_benchmark [options] A memcache/redis NoSQL traffic generator and performance benchmarking tool. Connection and General Options: -s, --server=ADDR Server address (default: localhost) -p, --port=PORT Server port (default: 6379) -S, --unix-socket=SOCKET UNIX Domain socket name (default: none) -P, --protocol=PROTOCOL Protocol to use (default: redis). Other supported protocols are memcache_text,
通过源码安装(离线安装依赖)
阿里云centos8.2 ,安装包网盘链接:https://pan.baidu.com/s/1in71h_K1nWqXGwA4ziSsqg?pwd=tetw
阿里云centos7.6 ,安装包网盘链接:https://pan.baidu.com/s/1LzLgCisk-aTqUwadYT-VIw?pwd=pf7r
使用方法同上《网盘安装包使用说明》
memtier_benchmark 参数介绍
[root@iZwz9f92w7soch5m251ghgZ bin]# ./memtier_benchmark --help
Usage: memtier_benchmark [options]
A memcache/redis NoSQL traffic generator and performance benchmarking tool.
Connection and General Options:
-s, --server=ADDR `Redis数据库的连接地址,默认是localhost`
-p, --port=PORT `Redis数据库的连接端口,默认是6379`
-S, --unix-socket=SOCKET UNIX Domain socket name (default: none)
-P, --protocol=PROTOCOL Protocol to use (default: redis). Other
supported protocols are memcache_text,
memcache_binary.
-a, --authenticate=CREDENTIALS `Redis数据库的密码`
A simple password is used for memcache_text
and Redis <= 5.x. <USER>:<PASSWORD> can be
specified for memcache_binary or Redis 6.x
or newer with ACL user support.
--tls Enable SSL/TLS transport security
--cert=FILE Use specified client certificate for TLS
--key=FILE Use specified private key for TLS
--cacert=FILE Use specified CA certs bundle for TLS
--tls-skip-verify Skip verification of server certificate
--sni=STRING Add an SNI header
-x, --run-count=NUMBER `迭代次数`
-D, --debug Print debug output
--client-stats=FILE Produce per-client stats file
-o, --out-file=FILE Name of output file (default: stdout)
--json-out-file=FILE Name of JSON output file, if not set, will not print to json
--hdr-file-prefix=FILE `HDR延迟直方图输出文件的前缀,如果未设置,将不会保存延迟直方图文件`
--show-config Print detailed configuration before running
--hide-histogram Don't print detailed latency histogram
--print-percentiles Specify which percentiles info to print on the results table (by default prints percentiles: 50,99,99.9)
--cluster-mode `当redis实例为cluster集群时,使用集模式选项,每个memtier客户端为每个节点打开一个连接。`
`因此,当使用大量线程和客户端时,用户必须验证自己不受文件描述符最大数量的限制。`
-h, --help Display this help
-v, --version Display version information
Test Options:
-n, --requests=NUMBER `设置每个memtier_benchmark客户端的总请求数,默认10000`
-c, --clients=NUMBER `表示每个线程的连接数(客户端数),默认50个客户端连接`
`测试中,一般采用策略:不断调整客户端连接数,得到每秒最大操作数。`
-t, --threads=NUMBER `设置每个memtier_benchmark客户端的线程数量,默认4个线程`
--test-time=SECS `测试时长(单位:秒)`
`当设置-n时,--test-time 无效`
--ratio=RATIO `测试命令的读写比率(SET:GET Ratio,default: 1:10)`
--pipeline=NUMBER Number of concurrent pipelined requests (default: 1)
--reconnect-interval=NUM Number of requests after which re-connection is performed
--multi-key-get=NUM Enable multi-key get commands, up to NUM keys (default: 0)
--select-db=DB `选择数据库DB编号`
--distinct-client-seed Use a different random seed for each client
--randomize random seed based on timestamp (default is constant value)
Arbitrary command:
--command=COMMAND Specify a command to send in quotes.
Each command that you specify is run with its ratio and key-pattern options.
For example: --command="set __key__ 5" --command-ratio=2 --command-key-pattern=G
To use a generated key or object, enter:
__key__: Use key generated from Key Options.
__data__: Use data generated from Object Options.
--command-ratio The number of times the command is sent in sequence.(default: 1)
--command-key-pattern Key pattern for the command (default: R):
G for Gaussian distribution.
R for uniform Random.
S for Sequential.
P for Parallel (Sequential were each client has a subset of the key-range).
Object Options:
-d --data-size=SIZE `表示单条数据大小,单位byte(default: 32)`
--data-offset=OFFSET Actual size of value will be data-size + data-offset
Will use SETRANGE / GETRANGE (default: 0)
-R --random-data Indicate that data should be randomized
--data-size-range=RANGE Use random-sized items in the specified range (min-max)
--data-size-list=LIST Use sizes from weight list (size1:weight1,..sizeN:weightN)
--data-size-pattern=R|S Use together with data-size-range
when set to R, a random size from the defined data sizes will be used,
when set to S, the defined data sizes will be evenly distributed across
the key range, see --key-maximum (default R)
--expiry-range=RANGE Use random expiry values from the specified range
Imported Data Options:
--data-import=FILE Read object data from file
--data-verify Enable data verification when test is complete
--verify-only Only perform --data-verify, without any other test
--generate-keys Generate keys for imported objects
--no-expiry Ignore expiry information in imported data
Key Options:
--key-prefix=PREFIX Prefix for keys (default: "memtier-")
--key-minimum=NUMBER Key ID minimum value (default: 0)
--key-maximum=NUMBER Key ID maximum value (default: 10000000)
--key-pattern=PATTERN Set:Get pattern (default: R:R)
G for Gaussian distribution. `高斯模式`
R for uniform Random. `随机模式
S for Sequential. `顺序模式`
P for Parallel (Sequential were each client has a subset of the key-range).
--key-stddev The standard deviation used in the Gaussian distribution
(default is key range / 6)
--key-median The median point used in the Gaussian distribution
(default is the center of the key range)
WAIT Options:
--wait-ratio=RATIO Set:Wait ratio (default is no WAIT commands - 1:0)
--num-slaves=RANGE WAIT for a random number of slaves in the specified range
--wait-timeout=RANGE WAIT for a random number of milliseconds in the specified range (normal
distribution with the center in the middle of the range)HDR延迟直方图在线分析:http://hdrhistogram.github.io/HdrHistogram/plotFiles.html
常用命令(ntcd)
memtier_benchmark -s {IP} -n {nreqs} -c {connect_number} -t 4 -d {datasize}若实例类型为cluster集群,则命令为
memtier_benchmark --cluster-mode -s {IP} -n {nreqs} -c {connect_number} -t 4 -d {datasize}
华为云Redis 4.0/5.0 主备实例测试
redis-benchmark -h {IP} -p {Port} -a {password} -n {nreqs} -r {randomkeys} -c {connection} -d {datasize} -t {command}参数参考值:-c {connect_number}:1000,-n {nreqs}:10000000,-r {randomkeys}:1000000,-d {datasize}:32。
参考链接:https://support.huaweicloud.com/pwp-dcs/dcs-pwp-0606004.html
华为云Redis 4.0/5.0 Cluster集群测试
memtier_benchmark --cluster-mode --ratio=(1:0 and 0:1)-s {IP} -n {nreqs} -c {connect_number} -t 4 -d {datasize}参数参考值:-c {connect_number}:1000,-n {nreqs}:10000000,-r {randomkeys}:1000000,-d {datasize}:32。
参考链接:https://support.huaweicloud.com/pwp-dcs/dcs-pwp-0606005.html
阿里云社区版(集群版-双副本)测试
memtier_benchmark -s r-***.aliyuncs.com -p 6379 -a <password> -c 20 -d 32 -t=10 --ratio=1:1 --test-time=1800 --select-db=10测试结果:https://help.aliyun.com/document_detail/100453.html
选项说明
| 选项 | 说明 |
|---|---|
| -s | Redis数据库的连接地址 |
| -n | 每个memtier_benchmark客户端的总请求数,默认10000 |
| -t | 每个memtier_benchmark客户端启动的线程数量,默认4 |
| -c | 每个线程的redis连接数(客户端数),默认50 |
| -d | 单条数据大小,单位byte,默认32 |
| -r | 使用随机key数量 |
| –cluster-mode | 集群模式 |
| –ratio | 读写比例 SET:GET,1:0 表示纯写,0:1表示纯读, 默认是1:10 |
| –test-time | 基准测试时长,单位秒。(-n和–test-time不能同时使用) |
| –select-db | 选择数据库编号 |
模拟并发连接数= *-t * -c*
总请求数1w,启动2个线程,每个线程20个redis连接数,存写
[root@iZwz9f92w7soch5m251ghgZ bin]# ./memtier_benchmark -s 127.0.0.1 -p 6379 -n 10000 -t 2 -c 20 --ratio=1:0 Writing results to stdout [RUN #1] Preparing benchmark client... [RUN #1] Launching threads now... [RUN #1 100%, 5 secs] 0 threads: 400000 ops, 69578 (avg: 73306) ops/sec, 5.23MB/sec (avg: 5.52MB/sec), 0.57 (avg: 0.54) msec latency 2 Threads 20 Connections per thread 10000 Requests per client ALL STATS ============================================================================================================================ Type Ops/sec Hits/sec Misses/sec Avg. Latency p50 Latency p99 Latency p100 Latency KB/sec ---------------------------------------------------------------------------------------------------------------------------- Sets 73036.04 --- --- 0.54527 0.26300 7.80700 14.52700 5626.56 Gets 0.00 0.00 0.00 --- --- --- --- 0.00 Waits 0.00 --- --- --- --- --- --- --- Totals 73036.04 0.00 0.00 0.54527 0.26300 7.80700 14.52700 5626.56测试过程中,检查redis连接数为:40=2个线程*20个连接数,注意连接数不能大于redis设置的最大值maxclients
127.0.0.1:6379> info Clients # Clients connected_clients:41 cluster_connections:0 maxclients:10000 client_recent_max_input_buffer:32 client_recent_max_output_buffer:0 blocked_clients:0 tracking_clients:0 clients_in_timeout_table:0测试结束后,检查数据库数据量如下:1w
127.0.0.1:6379> info keyspace # Keyspace db0:keys=9996,expires=0,avg_ttl=0测试结果分析:
存写性能:40并发(-t * -c) - 测试总耗时:5s - OPS/sec:73036 - 网络带宽:5626.56 KB/sec - 99% 响应延时:7.8 msec
memtier_benchmark 性能测试案例
案例一:华为DCS Redis实例的性能评估
测试步骤:
创建Redis缓存实例。
创建3台弹性云服务器(ECS),ECS选择与实例相同可用区、VPC、子网和安全组。
在每台ECS上安装memtier_benchmark
每台ECS上执行测试命令。
memtier_benchmark -s {IP} -n {nreqs} -c {connect_number} -t 4 -d {datasize}参数参考值:-c {connect_number}:200,-n {nreqs}:10000000,-r {randomkeys}:1000000,-d {datasize}:32。
- -t表示基准测试使用的线程数量
- -c表示客户端连接数
- -d表示单条数据大小,单位byte
- -n表示测试包数量
- -r表示使用随机key数量
不断调整客户端连接数,执行4,得到每秒最大操作数。
取3台测试ECS得到的每秒操作数总和,即为对应规格的性能数据。
如果测试Redis集群,建议每台测试ECS各开启两个benchmark客户端。
参考:https://support.huaweicloud.com/redisug-nosql/nosql_pwp_0015.html
案例二:亚马逊 R6g与R5缓存实例性能对比测试
环境信息
ElastiCache for Redis选择默认参数,开启了集群模式(Cluster),数据用3个分片(每个分片1主2从,合计9个节点,为了系统的高可用和管理需要,默认参数会设置25%的内存作为预留内存)
我们把测试客户端和集群的主节点人工强行放到了同一个 AZ 以获取更直接的对比效果,同时选用的 ElastiCache for Redis 集群实例(3*3 的 2xlarge 构建的集群)和测试客户端(8xlarge 的 EC2)均支持 10G 的带宽模式,读者在自己做测试时也要避免因网络带宽不足导致的测试结果失真。
(如果要测试集群的极限,建议采用多客户端的分布式测试方式)
测试场景
此处我们设定四个场景,为如下条件的组合:
- 随机测试:分别测试 500 和 1000 并发,键值 1k 到 4k 大小随机,测试时间 180 秒,SET 和 GET 的比例为 1:4;
- 正态分布(高斯分布)测试:分别测试 500 和 1000 并发,键值 1k 到 4k 大小随机,测试时间 180 秒,SET 和 GET 的比例为 1:4;
我们没有设置更高的并发或更大的键值测试,因为在测试的过程中,我们发现系统运行比较稳定,调高并发或键值会导致本文的测试客户端 m5.8xlarge 的带宽使用率直接打满 10G(如果要测试集群的极限,建议采用多客户端的分布式测试方式,本文暂不涉及),我们的测试命令只包括 SET 和 GET,且为了更好的模拟实际生产环境中的读写比例,所以此处读写比例设置为 1:4(模拟 20%写)。
测试场景 2-1:随机测试,500 并发,键值 1k-4k 随机大小,测试时间 180 秒,SET 和 GET 比例为 1:4
memtier_benchmark -R --data-size-range=1024-4096 --data-size-pattern=S --test-time 180 -t 10 -c 50 --cluster-mode --ratio=1:4 -p 6379 -s r5-redismemtier_benchmark -R --data-size-range=1024-4096 --data-size-pattern=S --test-time 180 -t 10 -c 50 --cluster-mode --ratio=1:4 -p 6379 -s r6g-redis
测试场景 2-2:随机测试,1000 并发,键值 1k-4k 随机大小,测试时间 180 秒,SET 和 GET 比例为 1:4
memtier_benchmark -R --data-size-range=1024-4096 --data-size-pattern=S --test-time 180 -t 20 -c 50 --cluster-mode --ratio=1:4 -p 6379 -s r5-redismemtier_benchmark -R --data-size-range=1024-4096 --data-size-pattern=S --test-time 180 -t 20 -c 50 --cluster-mode --ratio=1:4 -p 6379 -s r6g-redis
测试场景 2-3:正态分布(高斯分布)测试,500 并发,键值 1k-4k 随机大小,测试时间 180 秒,SET 和 GET 比例为 1:4
memtier_benchmark -R --data-size-range=1024-4096 --data-size-pattern=S --test-time 180 -t 10 -c 50 --cluster-mode --key-pattern=G:G -p 6379 -s r5-redismemtier_benchmark -R --data-size-range=1024-4096 --data-size-pattern=S --test-time 180 -t 10 -c 50 --cluster-mode --key-pattern=G:G -p 6379 -s r6g-redis
测试场景 2-4:正态分布(高斯分布)测试,1000 并发,键值 1k-4k 随机大小,测试时间 180 秒,SET 和 GET 比例为 1:4
memtier_benchmark -R --data-size-range=1024-4096 --data-size-pattern=S --test-time 180 -t 20 -c 50 --cluster-mode --key-pattern=G:G -p 6379 -s r5-redismemtier_benchmark -R --data-size-range=1024-4096 --data-size-pattern=S --test-time 180 -t 20 -c 50 --cluster-mode --key-pattern=G:G -p 6379 -s r6g-redis
在测试过程中,我们发现系统运行非常稳定,所以每种场景测试了 6 次,然后取如下图所示的 Sets、Gets 和 Waits 的 p99 均值
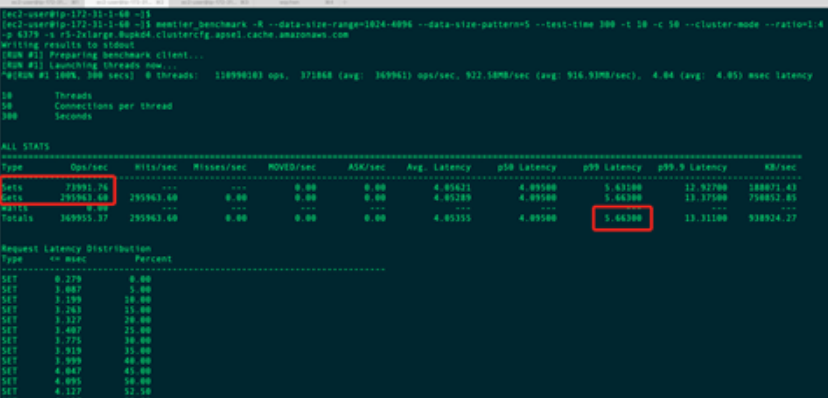
在测试客户端,每一次使用 memtier_benchmark 测试都会输出对应的网络流量,记得别超过实例的最高值即可,否则请使用多个实例的分布式并发测试
对比分析
针对之前的混合读写测试场景,我们针对 memtier_benchmark 工具的 4 个不同场景各做了 6 轮测试(每次重新开始测试前使用“flushdb/flushall”清理集群中的 3 个主分片,我们发现测试的结果非常的接近,表示服务器端运行稳定),获取到的原始数据如下:
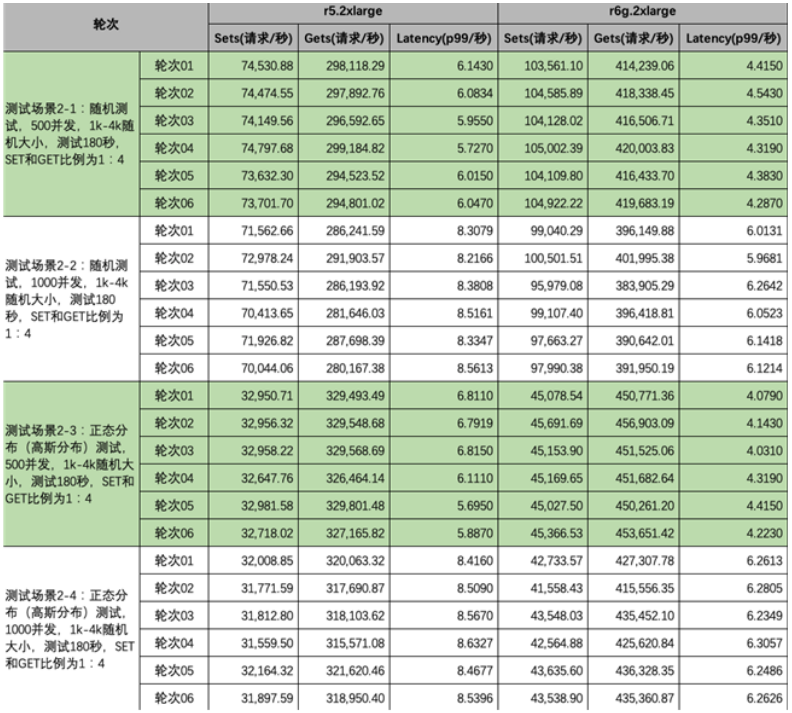
写入性能对比(每秒SET数值越大越好)
在场景 2-1 中,r6g 对比 r5,其 SET 的每秒请求数提升了 40%;
在场景 2-2 中,r6g 对比 r5,其 SET 的每秒请求数提升了 37%;
在场景 2-3 中,r6g 对比 r5,其 SET 的每秒请求数提升了 37%;
在场景 2-4 中,r6g 对比 r5,其 SET 的每秒请求数提升了 34%;读取性能对比(每秒GET数值越大越好)
在场景 2-1 中,r6g 对比 r5,其 GET 的每秒请求数提升了 40%;
在场景 2-2 中,r6g 对比 r5,其 GET 的每秒请求数提升了 37%;
在场景 2-3 中,r6g 对比 r5,其 GET 的每秒请求数提升了 37%;
在场景 2-4 中,r6g 对比 r5,其 GET 的每秒请求数提升了 34%;响应延时对比(响应延时数值越小越好)
在场景 2-1 中,r6g 对比 r5,其 p99(99%)的响应延时降低了 36%;
在场景 2-2 中,r6g 对比 r5,其平均响应延时降低了 37%;
在场景 2-3 中,r6g 对比 r5,其 p99(99%)的响应延时降低了 50%;
在场景 2-4 中,r6g 对比 r5,其平均响应延时降低了 36%;结论
同样条件下的性能测试和延时,R6g 机型(基于 Graviton 第 2 代的 ARM 架构)均大幅领先原有基于通用 CPU 的 R5 机型。通过测试我们可以清楚地看到,无论是何种工作负载和并发条件,R6g 实例比之同等资源配置的 R5 实例性能均有显著的提升。
redis性能测试注意的地方
建议施压机与redis实例在同个AZ,减少网络传输影响
检查施压机、redis实例所在主机带宽
在memtier_benchmark 测试结果中有使用流量数据,只要小于主机带宽即可,避免因带宽影响性能测试结果
检查redis实例所配置的最大redis连接数
避免因施压参数过大,超出最大redis连接数影响性能测试结果
检查使用过程中,redis实例主机内存、redis进程的内存使用情况
注意结合检查redis配置中的最大内存值,避免redis内存过大导致主机宕机
资源监控
主机带宽检查
使用speedtest-cli命令查看下载和上传最大流量值
pip install speedtest-cli[root@iZwz9f92w7soch5m251ghgZ ~]# speedtest-cli Retrieving speedtest.net configuration... Testing from Hangzhou Alibaba Advertising Co.,Ltd. (112.74.110.215)... Retrieving speedtest.net server list... Selecting best server based on ping... Hosted by HK Broadband Network (Hong Kong) [31.48 km]: 225.628 ms Testing download speed................................................................................ Download: 84.67 Mbit/s Testing upload speed................................................................................................ Upload: 5.77 Mbit/s
内存监控
查看系统内存(一段时间)
使用
sar查看内存 ,格式如sar 类型 类型参数(可选) 时间间隔 次数如果sar命令不存在,安装如下:
yum install sysstat内存利用率,使用sar -r命令
sar -r 1 1我们也可以查看指定的某一时间段内的记录
sar -f /var/log/sa/sa21 -s 14:50:00 -e 15:40:00-f:指定要读取的sa文件。
-s:开始的时间。注意,-s不是包含性的,所以必须从所选择的开始时间减去十分钟。
-e:结束的时间。
上述命令查看本月21日,15:00—15:30之间的记录。
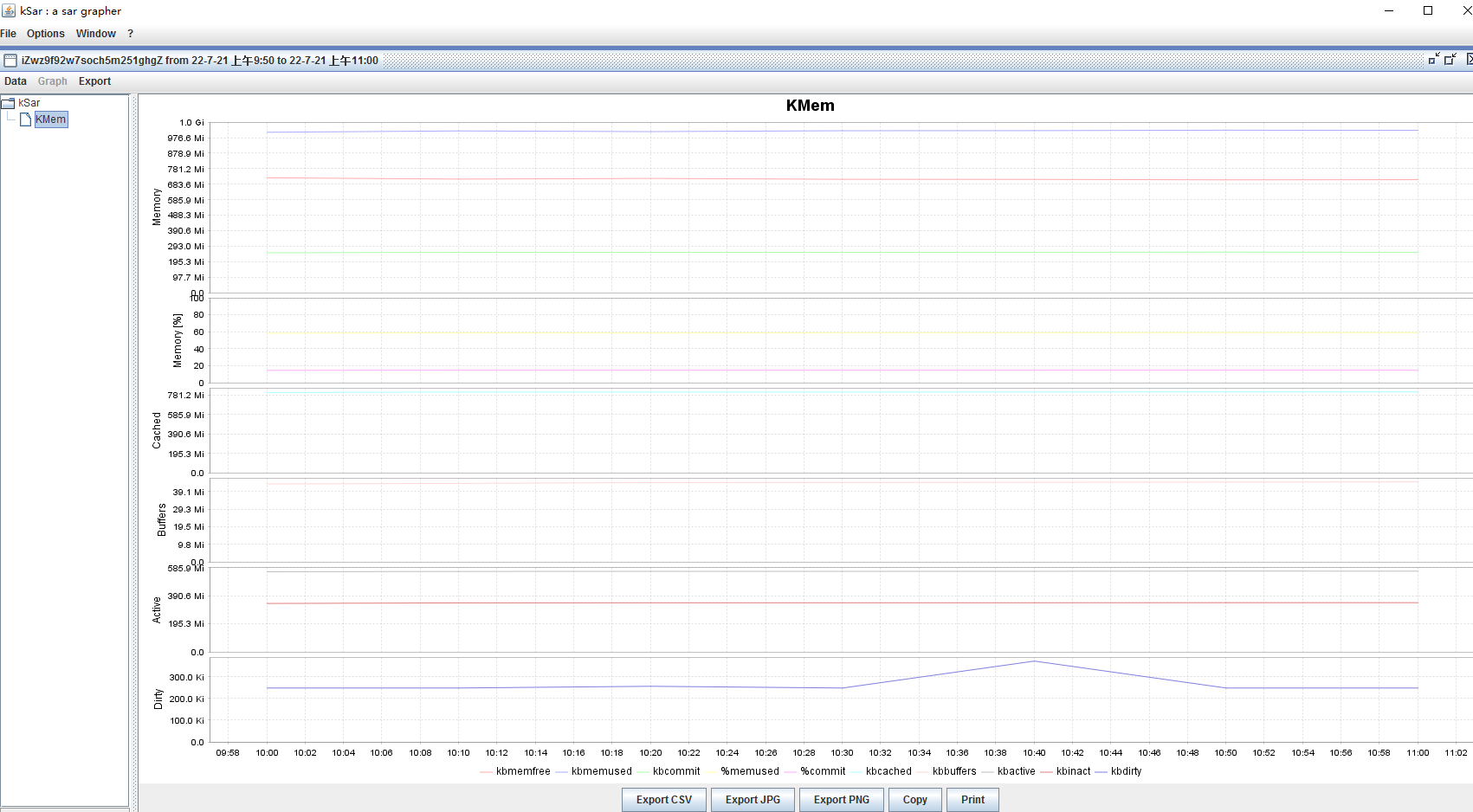
ksar这个工具可以将sar文件装换成图形,便于查看内存等数据的变化情况。
ksar 网盘下载:https://pan.baidu.com/s/1P7e3vMYiZFgF64qG6iam7g?pwd=6wgu
java -jar ksar-5.2.4-b396_gf0680721-SNAPSHOT-all.jarsar直接生成的sa
的文件,无法直接为ksar所用,要想生成可用的数据,我们需要导出sar为txt LANG=C sar -r -f /var/log/sa/sa21 -s 09:50:00 -e 11:10:00 > r_monitor.txt-A 表示导出所有数据,包括CPU、内存、IO、网络等等所有数据
-r 表示导出内存数据
不加LANG=C,sar文件显示的时间为12小时制;加LANG=C之后,sar文件显示的时间为24小时制。
[root@iZwz9f92w7soch5m251ghgZ ~]# free -m
total used free shared buff/cache available
Mem: 1734 93 711 0 929 1472
Swap: 0 0 0这里显示的kbmemused等于free -m 中的buff/cache+used
对于内核来讲,buff和cache都属于已经被使用的内存
当应用程序需要内存时,如果没有足够的free内存可用,内核会从buff和cache中回收内存来满足应用程序。
因此,从应用程序的角度,剩余可用内存 avaliable = free + buff + cache (理想的计算,实际有很大误差)
查看某进程的内存(实时)
在redis性能测试中,进程所占用内存过小,与Redis数据占用的内存相比可以忽略
ps aux | grep redis | grep 6379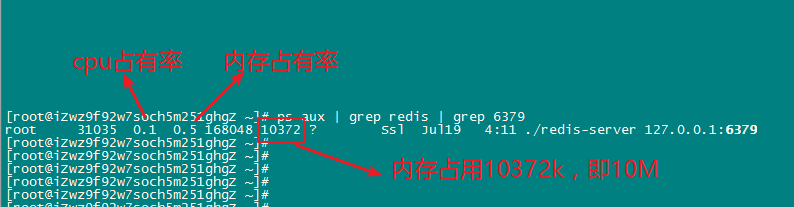
redis内存 info memory
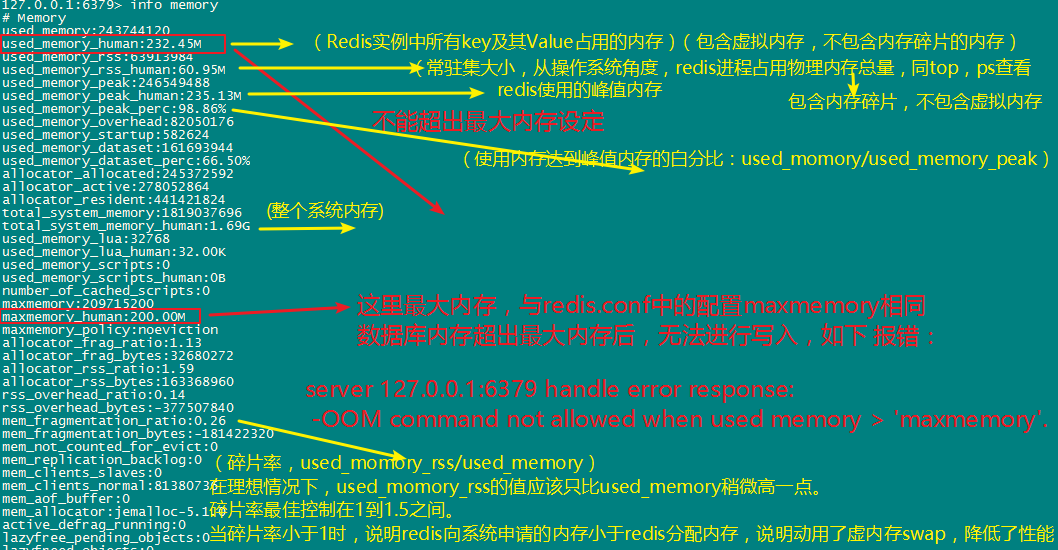
Redis主进程本身运行肯定需要占用内存,如代码、常量池等等;这部分内存大约几兆,在大多数生产环境中与Redis数据占用的内存相比可以忽略。这部分内存不是由jemalloc分配,因此不会统计在used_memory中。
redis_monitor.py 监控redis中的内存使用情况
# coding: utf-8
import commands
import time
import datetime
redis_connect="/usr/local/redis-6.2.7/bin/redis-cli -h 127.0.0.1 -p 6379"
def get_value(cmd):
status,output = commands.getstatusoutput(cmd)
value=str(output).strip().split(":")[-1]
dw=str(value)[-1]
value2=value.rstrip(dw)
if dw=="K":fm=1
if dw=="M":fm=1024
if dw=="G":fm=1024*1024
value_kb=float(value2)*fm
return value,value_kb
if __name__=='__main__':
cmd_maxmemory_human="%s info memory | grep maxmemory_human" % redis_connect
maxmemory,maxmemory_kb=get_value(cmd_maxmemory_human)
logfile="memmory_"+datetime.datetime.now().strftime('%Y-%m-%d-%H-%M-%S')+".log"
while True:
time.sleep(1)
current= datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
cmd="%s info memory | grep used_memory_human" % redis_connect
used_memory,used_memory_kb=get_value(cmd)
echo_cmd="echo {} maxmemory:{},used_momory:{},已占用:{:.2%} >> {}".format(current,maxmemory,used_memory,used_memory_kb/maxmemory_kb,logfile)
status,output = commands.getstatusoutput(echo_cmd)start_monitor.sh
#! /bin/sh
nohup python /root/mb_online/centos7.x/run/memtier/bin/redis_monitor.py 2>&1 > /dev/null &stop_monitor.sh:
#! /bin/sh
ps -ef | grep redis_monitor.py | grep -v grep | awk '{print $2}' | xargs kill -9转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。
